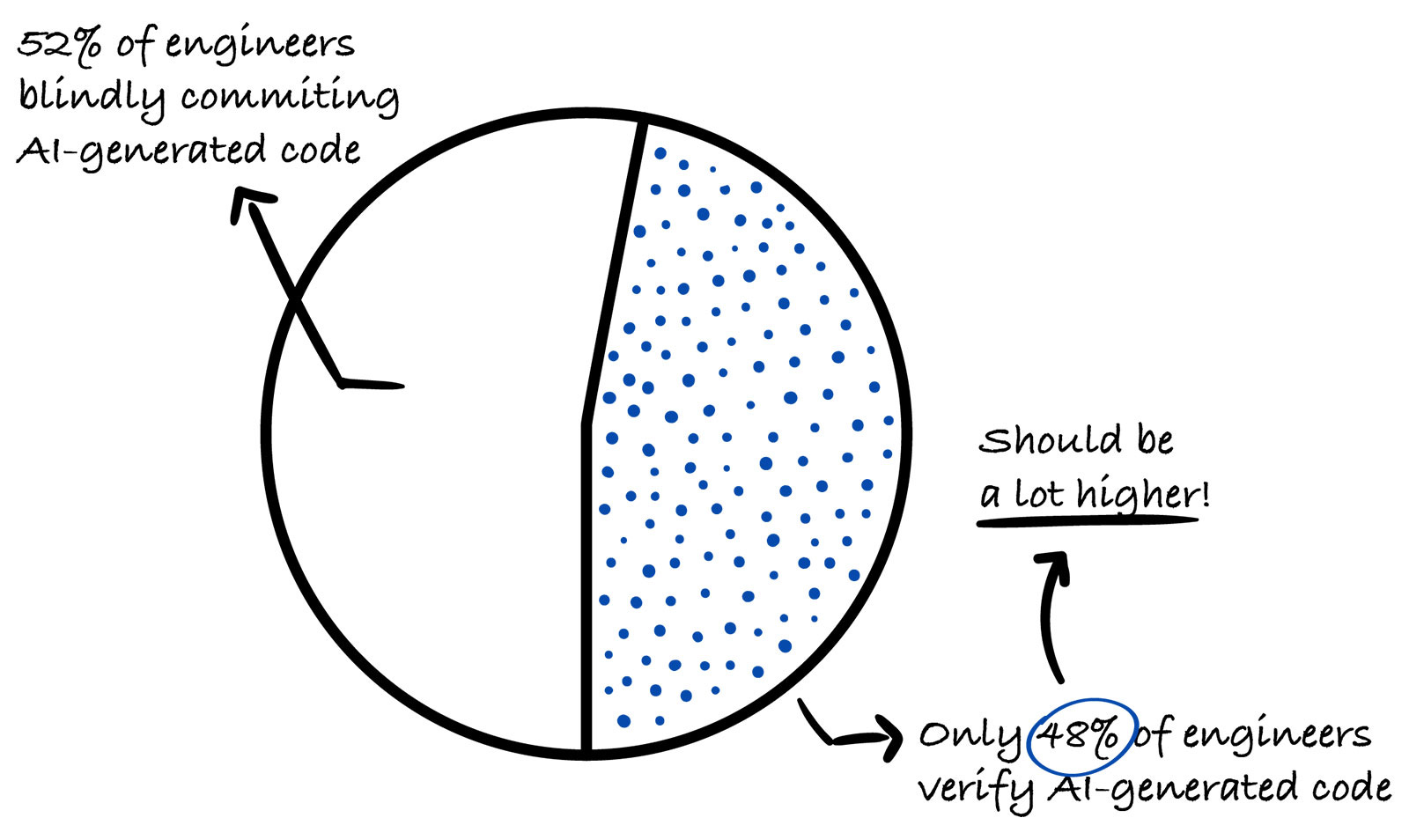
96% Engineers Don’t Fully Trust AI Output, Yet Only 48% Verify ItLatest report: How engineers use AI, do they trust it, and top AI toolsGregor OjstersekFeb 09, 2026∙ Paid4039ShareThis post is for paid subscribersSubscribeAlready a paid subscriber? Sign in