
How OpenAI Codex Tech Lead Does AI-Assisted Engineering
Michael Bolin, Tech Lead for the Codex open-source repo, is sharing how they built the permissions system with AI-assisted engineering.

Intro
I recently had the pleasure of visiting OpenAI’s offices in San Francisco, and one of the people I talked to there was Michael Bolin, a former Distinguished Engineer at Meta, now OpenAI Tech Lead for the Codex open source repo (Codex CLI).

Michael is also a fellow O’Reilly author, he wrote a book titled Closure: The Definitive Guide, dating back to 2010. Additionally, he created Buck, an open-source build tool at Meta, and he worked on Google Calendar during his time at Google.
We talked all about how he does AI-assisted engineering and what his workflow looks like. We went through a specific feature that he recently worked on, and what surprised me the most is that his workflow is very simple and straightforward.
Essentially, his workflow is the following: Write the spec → simple prompt → review the code.
No crazy AI workflows. Just clear thinking, good judgment, and fast iteration. I am sharing all the details on how he does it in this article!
This is an article for paid subscribers, and here is the full index:
- Building a permissions system within Codex CLI
- Writing requirements
- Initial implementation
- Handling merge conflicts
- Importance of keeping PR code sizes manageable and providing context with past PRs
- Codex creating PRs versus an engineer creating PRs in collaboration with Codex
🔒 Agentic PRs help doing more than 1 or 2 tasks at the time
🔒 Integration tests give a lot stronger signals than unit tests if the app is working correctly
🔒 Human code review versus AI code review
🔒 Example of how to use Codex to resolve an issue
🔒 Good fundamentals are crucial when doing AI-assisted engineering
🔒 Last words
Let’s start!
Building a permissions system within Codex CLI
We started our discussion with the project they recently finished, the permissions system within Codex CLI. He mentioned that the motivation behind building it within Codex is especially for Enterprise companies. Enterprises love features, but they also need constraints on which features can be used based on certain permissions.
Enterprises also care about keeping AI’s actions contained and secure, so it can only access and modify what it’s allowed to. So, ensuring that this is handled correctly, they also worked on features related to sandboxing.
This was a bigger project that the Codex team has worked on over several months.
Now, let’s go into how the project has started.
Writing requirements
The requirements have been written in a very simple way. Michael created a Notion document, where he described the requirements and functionalities that need to be supported. Basically a tech spec.

Then he asked the team to check and comment on the spec and specific parts of it. The team took a look, and everyone shared their perspective on what’s potentially missing or what could be done differently, which resulted in refining the initial design.
When that process was done, all the comments were addressed, and the team was happy with it, then they started with the implementation phase of the project.
Initial implementation
When it was time to implement the feature, they already had support for a Notion connector in Codex. So, instead of needing to copy and paste requirements in the context, Michael simply pasted the Notion URL into Codex and said, “Now I want to build this”.
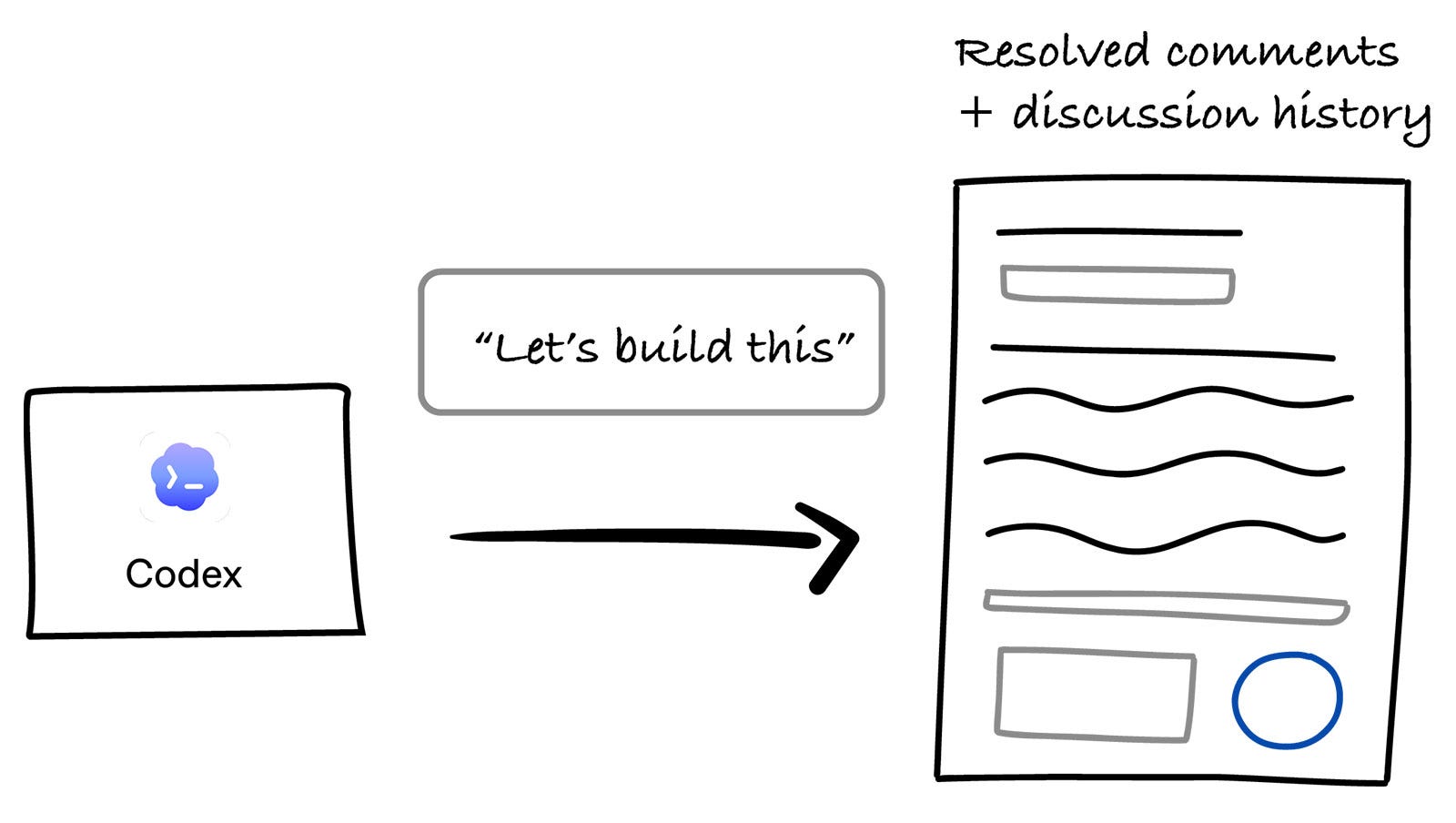
Because of the Notion connector, Codex was able to go directly to the source, read the requirements, comments, and discussion history. Michael explicitly mentioned that he really liked this part as it was much nicer than manually recreating all that context.
The first thing he asked Codex to do was create a plan and break the work into a set of right-sized pull requests.
Michael also mentioned that he doesn’t want 2,000-line PRs because a human still has to review them, which would make the experience very painful.
The initially generated code by Codex was around 6 PRs. They started working through them, reviewing the code, testing, handling merge conflicts, and doing refinements along the way.
That’s how their workflow essentially looked for building the project.
Handling merge conflicts
At this point, I asked Michael about handling merge conflicts for AI-generated code, as that can be quite painful, especially if you have many PRs open touching the same parts of the codebase.
He mentioned that Codex is actually a lot more disciplined when dealing with merge conflicts than he is. He created his own skill for dealing with merge conflicts, which is basically a specific set of instructions.
With the skill, as changes happen in parallel and files get modified by other engineers, he can simply let Codex handle a lot of that work consistently.
Importance of keeping PR code sizes manageable and providing context with past PRs
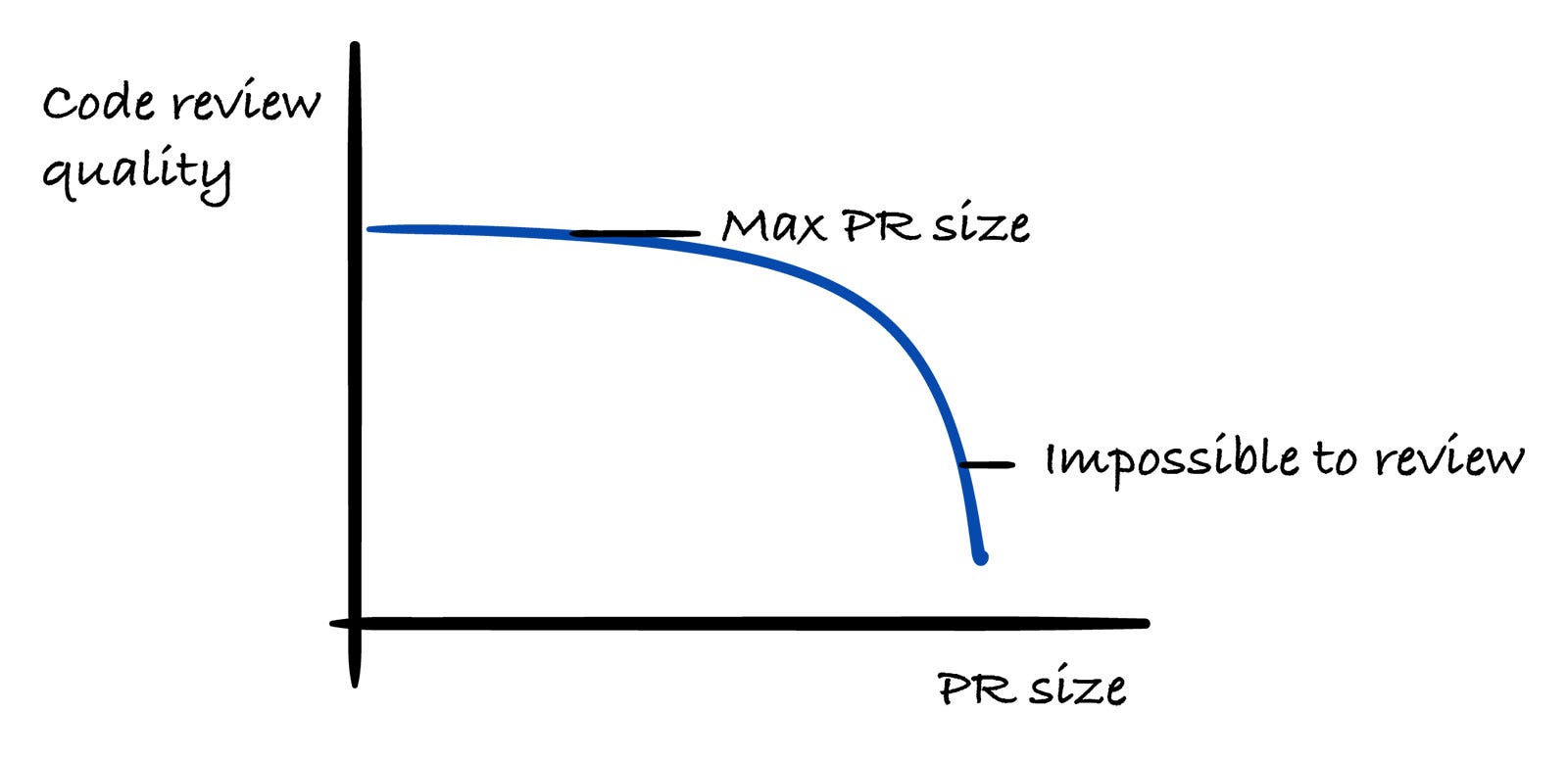
He mentioned that he’s a big advocate of creating right-sized pull requests. He often reminds Codex that a human needs to review the code, so changes should be broken into a size that is still reviewable.
Sometimes he explicitly tells it how he wants the work divided. Other times, he asks:
“Where does it make sense to split this change into smaller PRs?” or “How would you break this change into reviewable pieces?”
He also provides testing expectations when he has a specific validation strategy in mind.
Another practice he relies on heavily is referencing related pull requests. In fact, that’s often one of the most useful sources of context, he mentions.
Related PRs contain code, discussions, comments, and decisions. Giving Codex access to that context can significantly improve its understanding and output.
Additionally, he also mentioned that he occasionally rejects PRs opened by other people with the message of “PR being too large”, and that historically might have caused arguments because splitting work required effort.
Today, it’s much easier with AI coding tools. You can simply ask Codex to do it. That makes it much easier to enforce good review practices. The biggest thing is getting reviews down to the right size so it’s clear what each pull request is actually doing.
Codex creating PRs versus engineer creating PRs in collaboration with Codex
Or we could also call it Agentic PRs versus AI-assisted PRs. I know preference for most engineers these days is the second one, using Claude Code, Cursor, or Codex, while Michael has the preference for the first one (Codex creating PRs), which I asked him for the reasoning.
He mentioned that their CI takes around 15 to 20 minutes to run, and he wants Codex to create the pull request immediately so CI can start running as soon as possible.
They also have skills around what they call “babysitting PRs” or “babysitting CI”. Once the pull request exists, Codex watches for failures and can react to them automatically.
He also often tell Codex not to run most tests locally because CI will run the tests across Mac, Linux, and Windows anyway. He’d rather get the pipeline started immediately.
It also means, that he doesn’t need to have multiple full test suites consuming resources on his machine. Imagine, if you run 5-6 local changes at the same time, and all the tests start to run, the amount of compute it consumes on a local machine, makes it really hard to be productive.