
How to Do AI-Assisted Engineering
15 experienced engineers and engineering leaders share their real-world experiences with AI-assisted engineering.

This week’s newsletter is sponsored by Warp.
Introducing Oz: the orchestration platform for cloud agents
Engineers are shipping faster than ever, but agents stuck on local machines don’t scale. Without cloud agent orchestration, there’s no reliable way to scale across your infrastructure, measure impact, or enforce security standards.

Download the report to learn:
Why 75% of companies fail at building their own agentic systems
How teams save hours per engineer per day by using agent automations
What makes 60%+ of PRs agent-generated actually achievable
Thanks to Warp for sponsoring this newsletter. Let’s get back to this week’s thought!
Intro
In this special edition of the Engineering Leadership newsletter, engineers and engineering leaders share how they are doing AI-assisted engineering.
They come from a variety of backgrounds and a range of company sizes, from startups to mid-sized and large organizations.
Our contributors to this article are:
Brian Jenney, Senior Software Engineer, Coupa
Sam Williams, Head of Product Engineering, Pronetx
Owain Lewis, Founder, Gradientwork
Florijan Klezin, Data Engineer, Samotics
Vlad Khambir, Senior Software Engineer, Principal Associate, Capital One
Mauro Accorinti, Software Engineer, Qurable
Lucian Lature, Solutions Architect, Wiley
Tamás Csizmadia, Senior Java Software Engineer, Precognox Kft
Matthew Kyawmyint, Founding Engineer, Humanist Venture Studios
Hans Vertriest, Full-Stack Engineer, Bizzy
Uladzimir Yancharuk, Engineering Team Lead and Senior Full-Stack Engineer, Siena AI
Frances Coronel, Senior Software Engineer, Slack
Gilad Naor, Founder, Naor Tech
Anyell Cano, Staff Engineering Manager, GitHub
John Crickett, Founder and CTO, Coding Challenges
If you are looking to improve your AI-assisted engineering workflow, this is a must-read article for you.
Let’s start!
1. Coordinating AI-Assisted Engineering Across Multi-Repo Workflows, Side Projects, and Code Reviews
Shared by Brian Jenney, Senior Software Engineer, Coupa
Most of the work I’ve been doing spans multiple repos, so I first describe what I want to accomplish, such as “Create an IAM policy and relevant Terraform for repo A to do x, y, and z.”
I then explain the dependencies between the current repo and others that need to be updated, such as “Repo B needs an update to allow repo C to create the resources for repo A,” and provide good examples and files to illustrate what we are attempting to do. Lastly, I ask if the instructions are clear before proceeding.
For side projects, I create larger features in a smaller codebase and lean on AI more heavily to write code after creating a solid set of expectations and feature requirements. For example:
Create an endpoint at [fileName.ts] that does x, y, and z. Here’s an example endpoint doing something similar for reference. A UI component should be created here [someComponent.ts] that can call the API similar to this component [referenceComponent.ts]. Is this clear?
For code reviews at work, we have AI-assisted review in addition to human review. Human reviews tend to catch errors outside code syntax, like unexpected downstream effects or tribal knowledge.
We might get feedback like “This naming convention for that service won’t work because our script depends on this particular text to be present” or “That pattern is outdated and you can now use it this way to do this thing with a new library that we’re using.”
As far as I’m aware, we don’t use any AI tools for deployments that need a human review and final acceptance.
Our organization gives us access to both Claude and Cursor. I mostly use Claude, using Cursor rarely.
2. Building a Full AI Workflow on Top of Claude Code and Custom Skills
Shared by Sam Williams, Head of Product Engineering, Pronetx
Ideation
When generating ideas, we use Claude Cowork with a few skills. We have the option to use the BMAD (Build More Architect Dreams) Method, CCPM (Claude Code Project Manager), or our custom skill, all of which attempt to feed into our standardized requirements format.
These options get us better requirements and allow us to add our specific questions, which would normally cause a follow-up call.
Building
For building, we use Claude Code and a series of custom skills and Model Context Protocols (MCPs) tailored to our stack and architecture. We start by having AI convert the requirements document into a development plan.
We then review the plan and make any modifications. We catch quite a few things at this stage, such as requirements issues or needed improvements in the planning skill. Tests are written as you write the code.
We also have Claude run a second agent to review any tests written to make sure they aren’t just testing that a mock is a mock.
Review
We have a separate instance of Claude Code running on every pull request (PR), whether it’s human or AI generated. Quality assurance (QA) is still pretty manual right now, but we’re looking to have more automated end-to-end (E2E) tests.
3. Spending Half the Project on Design so AI Can Build the Rest
Shared by Owain Lewis, Founder, Gradientwork
I use AI across the entire engineering lifecycle. My primary model is Claude Opus 4.6 via Claude Code (the CLI tool) for all interactive work, layered with OpenAI Codex for automated background analysis.
The biggest productivity gain isn’t faster coding; it’s spending more time on design, because implementation is no longer the bottleneck.
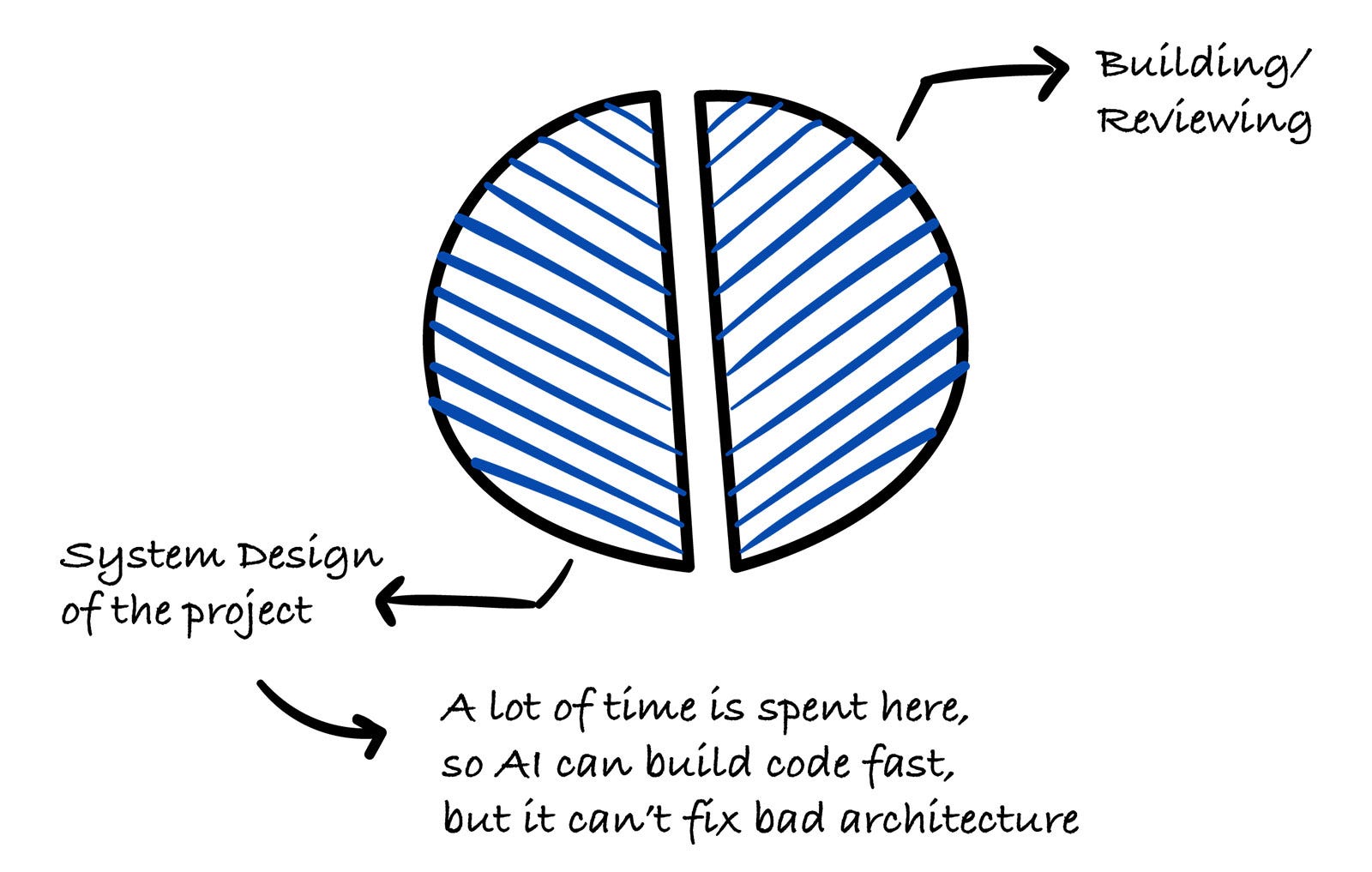
Ideation and design
This is where I spend the most time using AI, up to half of the project time. I feed raw requirements to Claude and get back an initial architecture: data model, API design, tech stack, and deployment strategy (design first).
Then I challenge every decision aggressively: “Do we need this table? What happens when this fails? Is this overspecified?” I go through multiple design versions before writing any code.
On a recent project, I did more than 10 design iterations on a simple project. AI can build code fast, but it can’t fix bad architecture.
Building
I delegate nearly all coding to AI. I write detailed specs first to ensure we build the right thing and use Linear MCP to capture tasks for agents to work on.
Although I’ve been writing code for more than 20 years, AI is generally better at it than any engineer I’ve worked with. But it does make mistakes and you must use your judgment to find them.
The design document becomes the implementation brief. I review and iterate every output, often multiple times. The first thing AI produces is a draft, not a deliverable.
For larger tasks, I run multiple Claude Code agents in parallel on different parts of the codebase.
Reviewing
AI might be better at writing code, but I’m better at knowing whether the code should exist at all. I review every file, then ask the AI to review its own output (”Review this like a senior engineer”).
This consistently catches issues the generation pass missed. I also use multiple agents to review from different angles: security, performance, correctness, simplicity, and so on.
On one project, an AI review pass found nine concrete issues before implementation. Five minutes of review saved hours of rework. Never trust the first output.
Merging and CI/CD
AI opens PRs with structured summaries and test plans and writes tickets with detailed descriptions. This is a huge time-saver and the quality is consistently better than human-written descriptions.
Claude Code also generates commits with clear messages and runs as an automated reviewer on every PR. OpenAI Codex runs nightly against my repos, scanning the full codebase, identifying bugs, and auto-opening tickets and PRs with fixes. It catches things I miss during the day.
I use AI heavily for operations work and debugging production issues.
Tools
I don’t use multiple AI tools because one is insufficient. I use them because they play different roles. For example, Claude is my interactive engineering partner, while Codex is my automated background quality gate.
Claude Code (CLI) with Opus 4.6: Primary tool for all engineering.
Claude Code agent teams: Multiple parallel agents for large tasks and multiperspective review.
OpenAI Codex: Automated nightly codebase analysis, which runs unattended, finding bugs and auto-opening tickets and PRs; I run different models to find errors in code.
GitHub Actions and Claude Code: AI-powered code review as a CI step on every PR.
Langfuse: Large language model (LLM) observability for AI-powered features in production.
uv (Python)/Bun (JS/TS): Fast package managers that keep the iteration loop tight.
Key lessons
AI doesn’t reduce iterations, it increases them.
Each one is faster, so you can afford more. Projects go wrong when someone accepts the first output and ships it.
The skill shift is from writing to reviewing.
Spotting subtle bugs, unnecessary abstractions, and confident-but-wrong AI claims requires deep experience.
Design documents are the most important artifact.
When AI generates code from them, their quality directly determines output quality.
You still need to know your craft.
AI makes experienced engineers dramatically more productive. It doesn’t make inexperienced engineers into experienced ones.
The formula: rigorous design + AI implementation + aggressive review + multiple iterations = high-quality output at speed.
The trap: no review + first-output acceptance = fast production of technical debt. The difference is discipline, not tooling.
4. Using Cursor as a Thinking Partner, Not Just an Autocomplete Tool
Shared by Florijan Klezin, Data Engineer, Samotics
I use Cursor as part of my daily engineering workflow because the repository indexing is strong, the pricing is reasonable, and I really like the overall IDE experience.
I can easily switch between models depending on the task, and the feature set is rich enough to support everything from large refactors to deeper architectural reasoning.
As a data engineer, I rely on AI for tasks like cross-file refactoring in data pipelines, generating integration tests, analyzing query plans, and running quick ad hoc analyses or plots to validate assumptions during investigations.
It’s more of a thinking partner than simple autocomplete, with output quality largely depending on how well I structure the problem up front.
5. Creating Reusable Workflows Rather Than Ad Hoc Prompts
Shared by Vlad Khambir, Senior Software Engineer, Principal Associate, Capital One
My approach to AI-assisted engineering centers on structured workflows rather than ad hoc prompting. Real productivity comes from applying AI to repeatable engineering patterns, not just isolated questions.
I’ve moved beyond using AI as a conversational assistant. Instead, I build reusable Windsurf Workflows that handle specific, recurring tasks, such as:
Pre-PR code review
PR preparation with consistent structure
Implementation planning from ticket requirements
Review of feedback processing
Each workflow is a structured prompt with defined inputs, expectations, and output formats. This eliminates the cognitive overhead of reexplaining context every time.
The biggest lesson I’ve learned is that AI doesn’t reduce work, it intensifies it. Poor context management leads to slower responses, degraded reasoning, and inconsistent results.
I apply the Agent Skills pattern (inspired by Claude’s approach) to separate three concerns:
Instructions: Markdown documents defining goals, constraints, and expected output
Resources: Static files, like style guides, templates, and internal docs
Scripts: Executable logic for external integrations (Git, Jira, etc.)
The Agent Skills keep the AI focused on reasoning instead of drowning in integration details.
Tools and stack
Windsurf: Primary AI coding environment with workflow support
Claude (via Xcode 26.3): For agentic coding with AGENTS.md, skills, and MCPs
Voice input: About twice as fast as typing, reducing the friction between thought and code
Custom linting and validation: Because AI generates tech debt faster if your process is messy
Balancing speed, structure, and human judgment
I don’t aim for full automation. Instead, workflows provide:
Structured feedback for code changes
Consistent PR descriptions
Implementation plans that respect architectural patterns
Categorized review feedback
The goal is to reduce friction and standardize routine work while keeping engineers in control.
From my experience building iOS apps with AI tools:
Tech debt accumulates faster. AI doesn’t replace a good process; it just amplifies your current process.
Hidden dependencies hurt more. That makes early dependency checks and clear agent rules essential.
Context limits are real. Be sure to separate the MCP responsibilities (data fetching) from reasoning tasks.
Speed isn’t free. If you want to ship faster, you need to debug faster.
AI tools intensify rather than reduce cognitive load. It’s like watching YouTube at double speed: You’re processing the information faster, but the mental demand increases with it.
The solution isn’t more AI; it’s better structure and clearer constraints. And it means accepting that you’re trading speed for a different kind of complexity.
This approach has helped me ship faster while maintaining quality, but only because I invested up front in workflow design and context discipline. I had to accept that AI is a force multiplier, not a replacement for engineering judgment.
6. AI-Assisted Engineering: Figma, Parallel Agents, and Learning New Tech on the Fly
Shared by Mauro Accorinti, Software Engineer, Qurable
Apart from how I am doing AI-assisted engineering, I’ll include how I’ve seen others use AI as well, since I believe that’s just as valuable.
Ideating
I’ve seen tech leads use AI to help write clear requirements in Jira tickets. The AI is given a definition of ready document, which it uses to divide the tasks into smaller chunks that the teams can take on.
AI is excellent for creating pretty clear tickets with descriptions, test cases, boundaries, and expected results.
With clearer tickets, it becomes easier to read and bring up edge cases to consider during our planning. It can be a massive time save for the tech lead, because AI can understand the tasks and create clear requirements.
Then they can just double-check the output and correct it on the spot.
Building
I’ve been building using AI agents for the last few months. Honestly, it’s changed a lot of how I work. Here are several examples.
Working with Figma MCP with IDE agents
With front-end work, my productivity has sped up a ton by using MCPs. Once set up, AI can view my Figma files and implement a design with 85–90% accuracy while integrating it to an existing Next.js project.
Things like text size or padding/margin spacing tend to be off, but the general positioning is there and I can correct the code to my liking.
I’ve found that the less accurate you are with the prompt, the worse the code is (e.g., adding font sizing to every p element instead of adding it once to the parent div element), but you learn to work with it as time goes on.
And you don’t always need to use MCP. I’ve found decent success using simple screenshots of the design.
Working with new frameworks/languages
AI has become a big help whenever I start working in repos with tech I’m not familiar with. I can now work faster and be more productive in these sorts of environments, thanks to AI helping me understand the repo better.
I describe my task to the agent, have it generate code, and then work with a separate AI to understand why the code does what it does. I can learn about the framework alongside doing my tasks in a way I couldn’t before.
I can ask questions about anything I might be worried about, like security, tests, requirements, and alternative ways to execute the same task, using common sense throughout.
This approach has cut down on the time I needed to learn about new tech before being able to work with it effectively. I run into fewer syntax and beginner errors with AI assisting me.
Doing tasks in parallel
I’m currently working on two projects. Sometimes I’m working on a big task in one project when a small task in the other project pops up.
If I have to, for example, disable a particular button while the form is submitting, I can give the task to the AI agent while I continue working in the other project.
After the AI agent’s work is done, I can quickly switch back to review the work and then create the PR, the code for which was being created while I worked on another task. This still seems crazy to me.
Helping create test cases
AI is honestly spectacular in creating unit tests for different features in a codebase. Once you create your feature, if you know what has to be tested, you can ask the agent to create the test suites needed. You can then check what was created and modify it to your specifications.
AI agents have become excellent at generating tests that don’t fail. They are now smart enough to run the test suite, detect any errors, and autocorrect until there aren’t any more before telling you the code is done.
Reviewing
In one of our projects, we use GitLab integrated with an AI that reviews all PRs and analyzes the code. This review is added as a comment to every PR.
This process does a few things. It compliments what’s good about the code and critiques elements that are missing, could be improved, or shouldn’t be included.
For example, it brings up warnings whenever you accidentally committed .envs, if the PR title doesn’t include the ticket, if test cases weren’t created or don’t consider a specific case, or if the code seems different from the rest of the specifications currently in the repo.
It’s a great first look while you wait for other devs to take a look at it.
7. Separating Generation from Verification Across the Pipeline
Shared by Lucian Lature, Solutions Architect, Wiley
When I’m doing AI-assisted engineering, I think of the AI as a high-speed collaborator throughout the entire pipeline, but I keep it on the rails with two rules: I separate generation from verification, and I separate conflicting goals into separate “modes,” or specialist agents, so security paranoia doesn’t undermine shipping and shipping pressure doesn’t undermine risk.
Building the right thing begins with ruthless problem framing
I start by writing down the problem statement, the target user, the outcome, the metric, and the non-goals. Then I use the AI to attack them, so that I get the assumptions that I must make true, the fastest way to kill those assumptions, and what I should not build.
If it’s a problem in multiple domains, I don’t use one general agent. I delegate to multiple modes, one to think about the product, one to think about the architecture, one to think about security, so that I get to the smallest testable slice with the clearest success criteria.
Design is interface-centric, tradeoff explicit
Before I write code, I have the AI to give me two plausible designs, and I force myself to make a decision by weighing cost, complexity, usability, failure cases, and so on. I define contracts early, so I know the API shape, the events, the error cases, and the data ownership.
This is where I’m likely to want to use the stronger “reasoning” model, since shallow suggestions are expensive to fix later. I also ground everything in the existing context, so that I don’t accidentally redebate old decisions or drift in style. I pull in existing decisions, conventions, and constraints so that I don’t relitigate old problems.
Implementation is where AI gives you the biggest speedup, but only with tight feedback loops
I use AI very heavily for scaffolding, repetitive glue code, mapping between different levels (schemas to types to handlers), and exploring different alternatives quickly. However, I do not use “big bang” AI commits. The cycle is generate, run, see how it goes, fix.
If I’m getting into very specialized domains, I use the appropriate expert: TypeScript-type system problems use a TypeScript-focused expert, React architecture uses a React-focused expert, infra or CI/CD uses a DevOps/SRE expert.
However, they all have one thing in common: They have smaller toolsets and domains that make them more accurate and cheaper than one monolithic expert.
Testing is intentionally adversarial and separate from code generation
I do not use the same expert that wrote the code to test it. I switch experts and ask for edge cases and negative cases and ask how this could break in production. Then I take actual bugs and turn them into regression tests immediately.
For critical paths, I’m biased toward integration tests over a forest of brittle unit tests. AI is helpful for this by coming up with cases and producing a first draft of tests. However, tests must always be deterministic, readable, and tied to a failure mode.
Code review is not one pass; it is a series of passes
I do code review in several passes: correctness and maintainability concerns first, then security concerns, and then design and performance risks. Each reviewer outputs a list of concerns with severity and location.
To do this efficiently, I use context reuse between review passes. The expensive structural understanding of the codebase is cached so that the second and third reviewers do not need to reparse everything and rediscover the same things.
Merging is about accountability, not automation
I use AI to write out the PR description, risk checklist, and test plan so that I have all clarity quickly.
However, I personally review the top-level risks just before merge because there is a risk of a “rubber stamp” problem as velocity increases and understanding decreases with AI adoption. I use it to reduce the review surface area to a minimum.
Monitoring and continuous improvement closes the loop
I define a small set of signals for each change: error rates, latency, saturation, and a single business signal if applicable.
I also use lightweight live evaluation for AI-heavy processes by sampling: cheap checks at high rates and expensive judging at lower rates. This is always done asynchronously so it does not add user-visible latency.
The tools I use to implement all of this are a cheap routing step to decide whether to use a large model, specialists for conflicting domains, hybrid retrieval so that the agent is connected to the world via real-world context, workflow primitives for repeatable patterns such as review and synthesis, and reliability primitives such as timeouts and retries so that a single stuck call does not block the entire system.