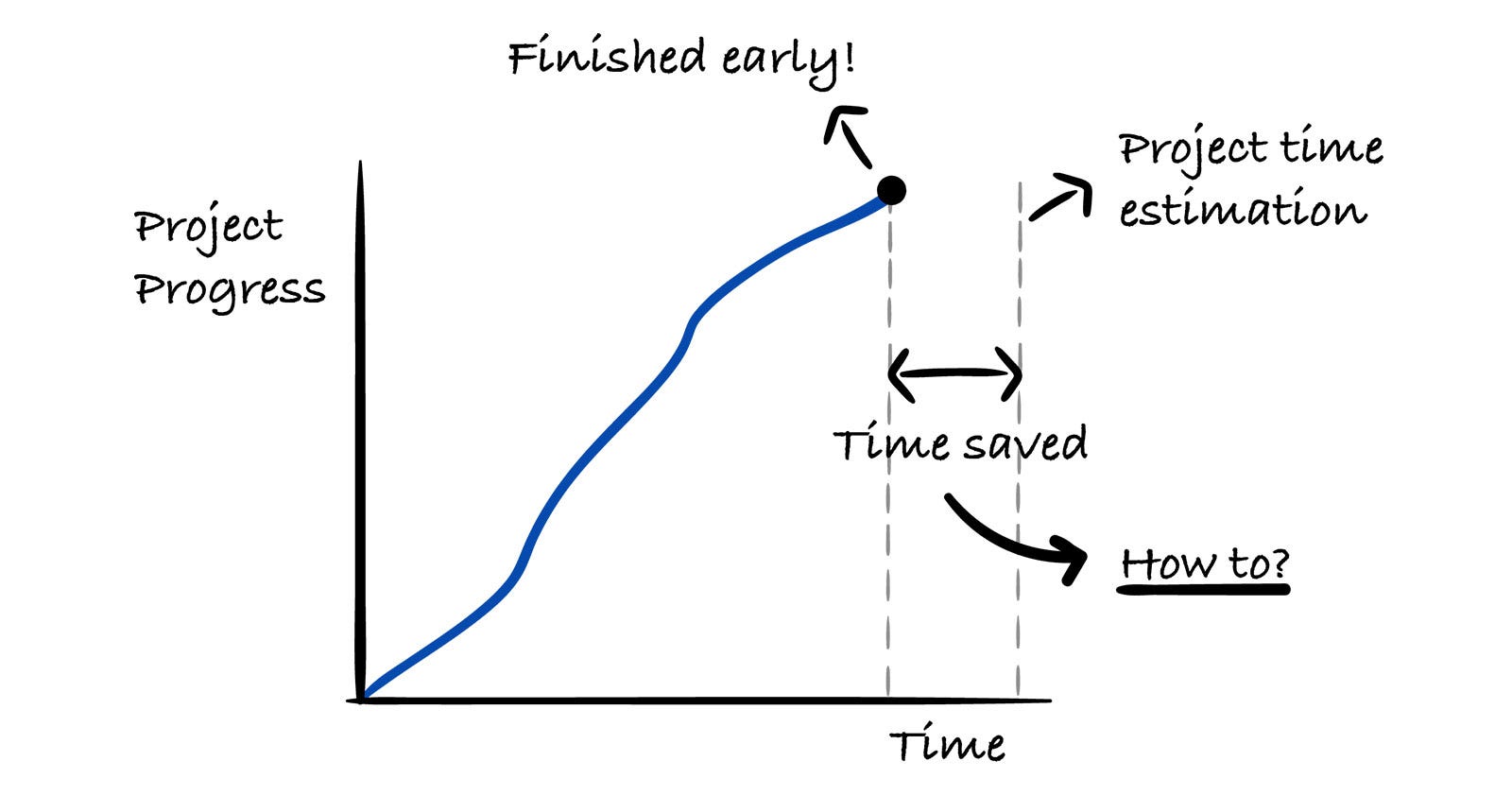
How to Finish Engineering Projects Early Without Added StressA real-world case study on using the critical chain methodology to finish projects early without added stress.Gregor Ojstersek and Karol WójciszkoMay 24, 2026∙ Paid741614ShareThis post is for paid subscribersSubscribeAlready a paid subscriber? Sign in