
LLMs: Common Terms Explained, Simply
What LLMs are, how they are trained, and how they can be used, visually explained!


Intro
Large Language Models (LLMs) have quickly become a hot topic in tech, business, and everyday conversations, but the jargon sometimes can make it a harder topic for daily discussion.
And also, what someone says can be interpreted differently, based on their understanding.
To ensure that you know all the main terms behind LLMs, read the simple explanations next and refer back to them whenever you need to.
When I first saw Ashish’s visuals, I immediately thought how clearly and simply these terms are explained!
Introducing Ashish Bamania
Ashish Bamania is an Emergency Medicine doctor by day and a self-taught Software Engineer and writer in his spare time. His goal with writing is to simplify the latest advances in AI, Quantum Computing & Software Engineering.

He recently published a book called LLMs In 100 Images, covering the most important concepts you need to understand Large Language Models.
I’ve asked him to share some of these great visuals in the article today to simplify how LLMs work, and luckily for us, he is kindly sharing many of the awesome visuals with us today!
Check out the book and use my code EL20 for 20% off.
LLMs are One of the Most Successful AI Technologies to Date
The LLM market is expected to reach a total value of $82 billion by 2033.
As of 2025, 67% of organizations worldwide have adopted LLMs to support their operations with generative AI.
If you’re new to LLMs and would love to deepen your knowledge, this article will help you do that.
Let’s begin!
What Are LLMs?
Large Language Models (LLMs) are AI systems that are trained on vast amounts of text data to understand and generate human-like language.
During training, they learn patterns, relationships, and structures in language by analyzing billions of text examples from books, articles, websites, and other written sources.
This gives them an understanding of grammar and semantics in human language.
Some of the popular LLMs used today are:
GPT-4o from OpenAI (in the form of ChatGPT)
Claude Sonnet 4 from Anthropic
Gemini 2.5 Flash from Google
These models are proprietary, which means that their internal details (weights, parameters, training data, training methods) aren’t publicly available.
The most widely used open-weight models, where model weights are publicly available, are:
Llama by Meta
DeepSeek-V3 by DeepSeek
Mistral Medium 3 by Mistral AI

What Powers An LLM?
The Transformer architecture is the backbone of all popular LLMs that we use today.
Transformer was developed through research by Google in 2017.
What makes it so good is that, unlike previous methods, it lets LLMs understand and process all words in the input text at the same time (in parallel, rather than one after another (sequentially).
This is achieved through its mechanism called Self-attention, which helps figure out how each word relates to every other word in the text sequence.
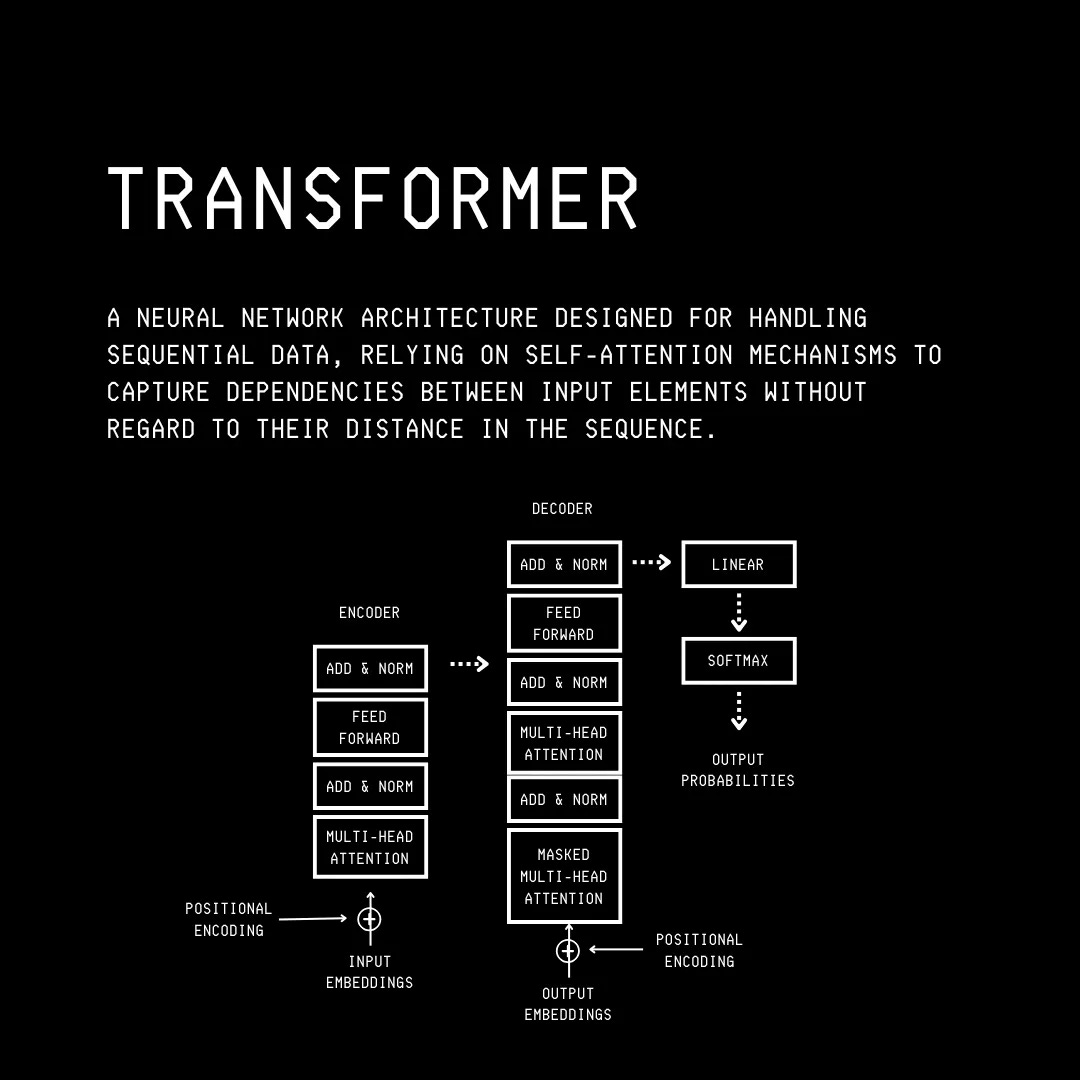
What makes it so good is that, unlike previous methods, it lets LLMs understand and process all words in the input text at the same time (in parallel, rather than one after another (sequentially).
This is achieved through its mechanism called Self-attention, which helps figure out how each word relates to every other word in the text sequence.

What Is GPT?
GPT or Generative Pre-trained Transformer is one of the earliest and most widely known LLMs.
GPT was born out of research from OpenAI in 2018, just one year after Google introduced the Transformer architecture.
Its successor, ChatGPT, is one of the most popular LLMs used today.

GPTs generate text by predicting the next word/token given a prompt.
This process is called Autoregression, which means that each word is generated based on the previous ones.

You’d see in the image describing GPT that it accepts Input Embeddings and Positional Encoding as inputs.
This seems strange because it should have been a word/ sentence that goes into the GPT for it to produce the next word.
The truth is that LLMs do not understand English (or any other human language).
Any word/ sentence in English has to be first broken down into small pieces called Tokens in a process called Tokenization.
In LLMs like ChatGPT, this is done using a Tokenization algorithm called Byte Pair Encoding.

The tokens obtained are then encoded into mathematical forms known as Embeddings.
Embeddings are high-dimensional vector representations that capture the semantic meaning and relationships between different words/ sentences.
Words with similar meanings have embeddings that are closer to each other in a higher-dimensional space.
This is shown below, where the embedding of “Apple” is closer to that of “Orange” than “Pen”.
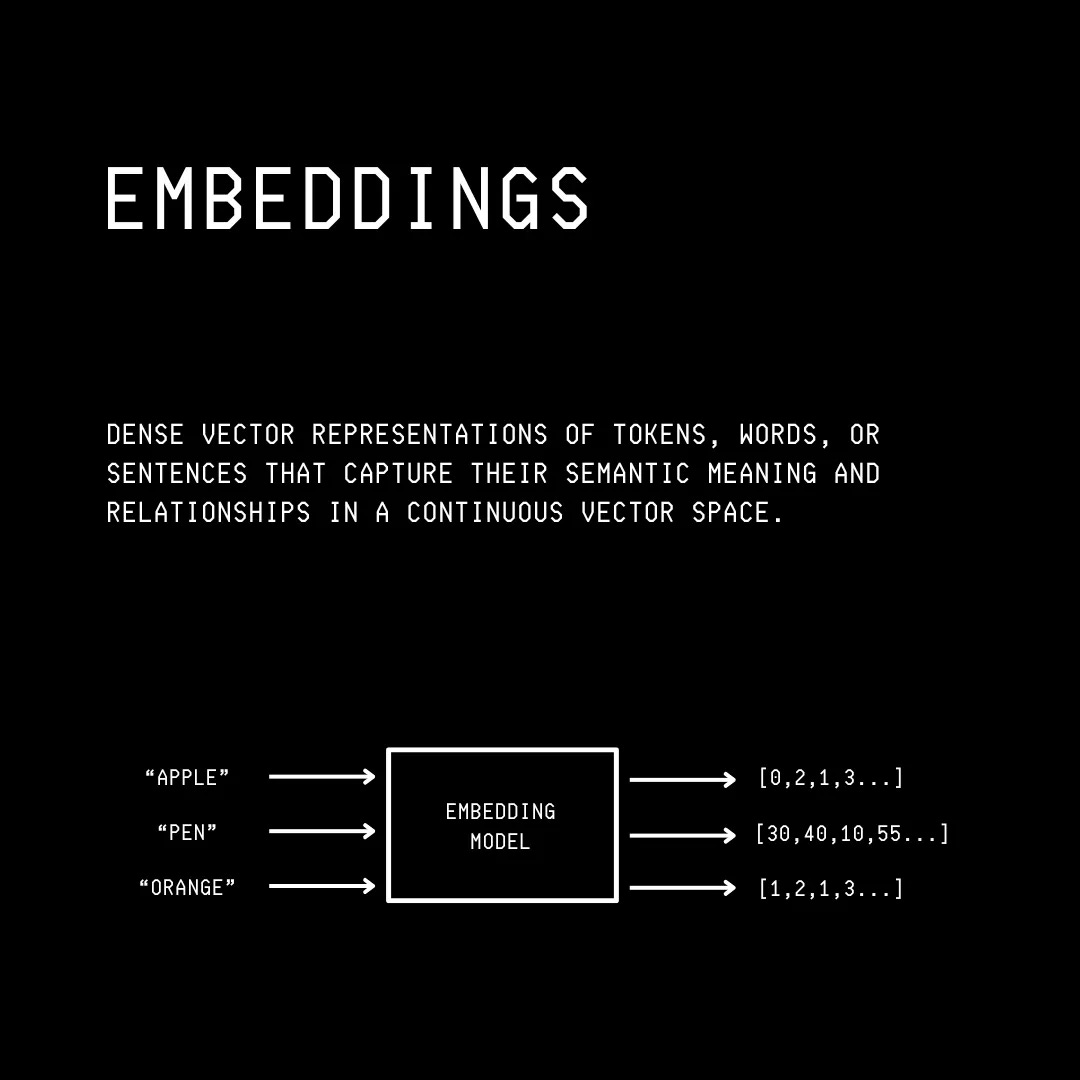
We have previously discussed how the Transformer architecture in LLMs lets them process all words/ tokens in parallel.
This could lead to issues because in a language like English, the positioning of words is important for conveying meaning.
This is why Positional Encodings are used to combine the positional information of different words/ tokens in a sentence with the input embeddings of those words/ tokens.

Now that we know about the internals of LLMs, let’s discuss how they are trained.
Training An LLM To Generate Text
 | A guest post by
|