
Meta Created an Internal Leaderboard on AI Token Usage
This seems to be a part of the broader trend in Silicon Valley called "tokenmaxxing". Here's what's happening.

Before we start with today’s article, a reminder.

As a paid subscriber, you are now able to ask any questions related to engineering/engineering leadership and get an opinion from like-minded people.
Share ideas, challenges, or get an opinion on the approach (you can start a new thread)
Connect with everyone
Special opportunities
This chat is available to 1700+ engineering leaders, who are paid subscribers from companies such as Meta, Google, OpenAI, and 500+ others.
Think of it as StackOverflow for Engineering Leadership, except no toxic behavior :)
I’ll also use this chat to provide special updates regarding the newsletter, new products, videos, early releases, and also provide special opportunities.
We started with introductions recently. And there’s also a special update on how you can get a free 1-month subscription to the O’Reilly platform.
Introduce yourself in the chat here:

Let’s get back to this week’s thought!
Intro
Over the past year, AI adoption inside tech companies has gone from experimentation to AI being an active part of the day-to-day of tech professionals.
At Meta, they’ve gone the next step. They created an internal leaderboard ranking employees based on how many AI tokens they use.
The problem with such a leaderboard is that if token usage becomes the metric, then token usage becomes the goal. And that’s where things can go sideways quickly.
And then the question that comes up as a side effect is: Are we actually becoming more productive with AI or just better at looking productive?
This is an article for paid subscribers, and here is the full index:
- A leaderboard called “Claudeonomics”
- This seems to be a part of the broader trend in Silicon Valley
- Using token consumption as a benchmark for productivity. The side effects
🔒 Is judging people based on token consumption the right way to go?
🔒 This is a trend that I am seeing all the way from early 2025
🔒 The same incentive is behind the trend of “tokenmaxxing”
🔒 Judging people based on token consumption
🔒 I rather look at these 4 specific things
🔒 Should you do something similar in your company?
🔒 Last words
Let’s start!
A leaderboard called “Claudeonomics”
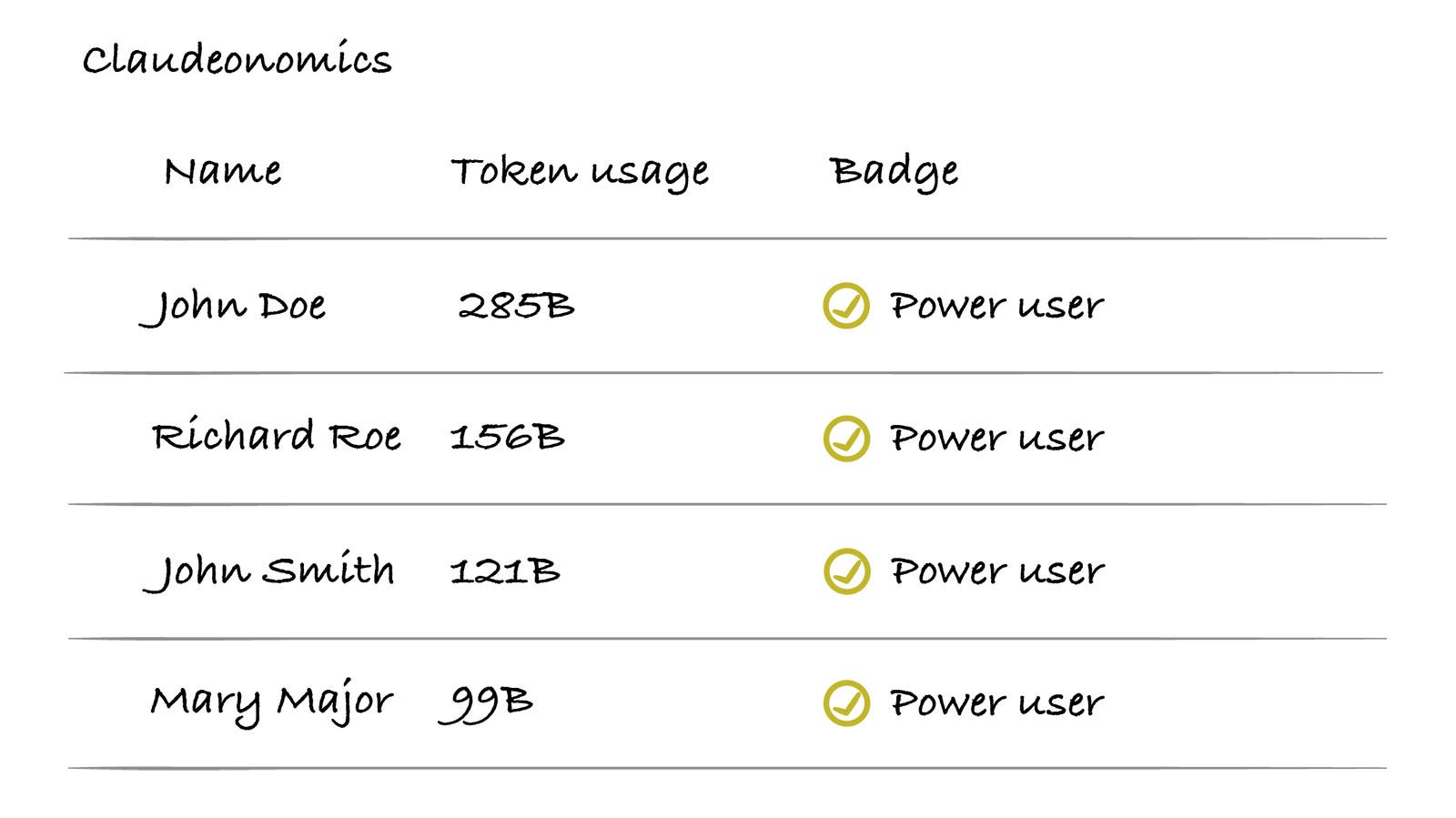
This is the name of the leaderboard at Meta, and it tracks AI token usage of over 85k employees. Interestingly, this has been a bottom-up initiative, built by engineers and shared on the company’s intranet.
Some unofficial data I have seen based on my research:
In the past 30 days, the total usage exceeded 60 trillion tokens
Estimated cost $900 million based on public pricing for the Claude Opus 4.6 model
The top individual user consumed 281 billion tokens
So, based on how much your token consumption is, the higher you are in the leaderboard.
There are also different badges, from bronze, silver, gold, platinum, to emerald, awarded to people, and the top 250 people in the leaderboard are considered “power users” and can get additional badges like “Session Immortal” and “Token Legend”.
So, it’s like a game of who is using the most tokens. But the actual question is:
Is the use of tokens actually going in the right direction? Solving actual business problems?
This seems to be a part of the broader trend in Silicon Valley
The trend seems to be called “tokenmaxxing”, where token consumption is treated as a benchmark for productivity and a competitive metric to determine if an employee is “AI-native”.
Here are some more examples (according to Forbes):
Nvidia CEO Jensen Huang
Stated that he would be “very concerned” if an engineer earning $500,000 annually spent less than $250,000 on AI tokens each year.
Ali Ghodsi, CEO of Databricks
Delivered a keynote to the company’s engineering team, where he highlighted a particular engineer who had used over $7,000 worth of AI tokens within just two weeks in January.
Rather than criticizing the high spending, Ghodsi used it as a positive example. And mentioned: “We actually had the whole engineering team applaud him and recognize his efforts. My goal is to encourage everyone to start using these tools.”
Andrew Bosworth, Meta CTO
Said at a tech conference in February that a top engineer who spent an amount equivalent to their salary on AI tokens saw a productivity increase of up to 10 times. And mentioned: “It’s a no-brainer, keep doing it, there is no upper limit.”
Andrej Karpathy, a former AI scientist at Tesla and OpenAI, now heading an AI education startup
Said on a podcast: “The name of the game is tokens. How can you maximize your token throughput and not be in the loop”.
Using token consumption as a benchmark for productivity. The side effects
I am also hearing the following: Some employees at Meta, in order to climb the leaderboard, they let AI agents run continuously for hours to perform research tasks, maximizing token consumption.
There seems to be a lot of other companies doing something similar as well, it’s not just Meta.
One engineer mentioned the following:
My company has been doing something like this as well, and it’s as stupid and easily gamed as you would expect. Right up there with measuring lines of code or using story points to gauge productivity.
The best way to rack up tokens seems to be keeping a chat context going for a long time, telling it to read tons of code (multiple repos for extra points), and pasting as much code or text into the chat as you can.
Another mentioned:
It’s official in the company I work for, but in our case, if you don’t reach an AI usage threshold each week, you are fired.
And there have been more similar cases like these. Some other engineers I talked to have also mentioned that they either are judged based on token usage in their company or they know someone who is.
Based on the company names, the majority of such companies are based in Silicon Valley. I believe the trend of “tokenmaxxing” is less common in companies outside of that bubble.
Now that we know what’s happening, let me share my take on whether this is the right thing to do and if your company should be doing something similar.