
What’s Really Like to Be an AI/ML Engineer
3 real-world examples of AI/ML Engineers -> their stack, challenges, and day-to-day focus!

This week’s newsletter is sponsored by Atono.
How we built an MCP server from scratch
MCP Servers has quietly become the thing every engineering team is adding to their roadmap. Not because it is trendy, but because it finally gives AI a safe and predictable way to work with the systems you have already built.
In Atono’s latest webinar, senior engineer Lex walks through how their team built an MCP server from scratch. He shares what the process looked like, where things got strange, and how LLMs behave once they are connected to real workflows instead of clean examples.

In this walkthrough, you’ll learn:
How MCP gives AI a predictable way to interact with your systems — even when your product has years of features, fixes, and tech debt baked in.
Why we built and shipped our MCP server as a Dockerized service — and how that choice simplified security, setup, and compatibility across tools like Zed, VS Code, and Copilot.
What happens when different LLMs start invoking your tools — including the unexpected behaviors, model quirks, and debugging patterns that only show up once everything is wired into real workflows.
Whether you manage a team or write the code, this walkthrough shows how MCP works in practice.
Thanks to Atono for sponsoring this newsletter, let’s get back to this week’s thought!
Intro
With the increase in popularity of AI, roles such as AI Engineer and ML Engineer are becoming more and more popular.
In order to understand the roles much better, I’ve asked 3 AI/ML Engineers to share their real-world experience:
How does their day-to-day look like
What technologies do they work with
Specific challenges they are facing
How does the work differ from Software Engineering
These are the 3 engineers I had the pleasure of talking to:
If you like these kinds of articles, where I talk to various engineers & engineering leaders and share their insights, you’ll love these 2 articles as well:


Let’s start!
1. Working on large scale ML systems at Meta with the focus on defending against bad actors
Shared by Shivam Anand, Staff ML Engineer at Meta.
His work focuses on large-scale machine learning systems, with a particular emphasis on adversarial ML → building resilient systems to defend against bad actors.
Before Meta, he spent over seven years at Google, leading ML efforts in ads spam and fraud, video ranking, and search quality.
What attracted him to AI/ML was how fast the field evolves. He always loved learning, and ML is one of the few areas in engineering where the landscape can shift dramatically year to year. That constant state of reinvention is what kept him engaged.
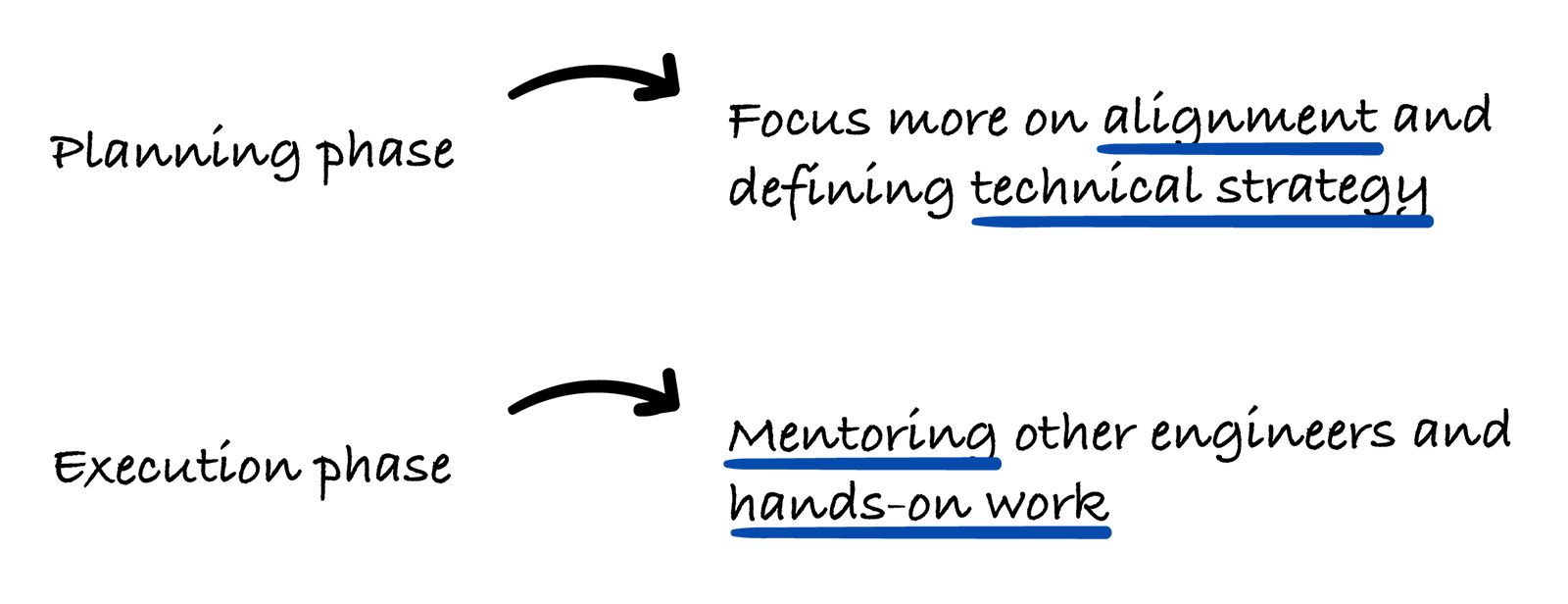
At Meta, his day-to-day varies depending on the time of year. During planning phases, the focus is on alignment and defining technical strategy.
In execution phases, it shifts to mentoring other engineers and hands-on work → building infra, training models, iterating quickly.
He uses PyTorch extensively, tightly integrated with Meta’s internal stack. A major focus area has been deploying LLAMA models to handle problems where labels are scarce and adversarial behavior is dynamic.
One of the hardest problems he tackled recently involved scaling LLMs to handle billions of unknown examples with only a handful of positive labels.
It’s an extreme version of the class imbalance problem, where success depends not just on modeling, but on optimizing data pipelines, evaluation strategies, and inference performance across infrastructure.
Compared to earlier roles in software engineering, ML introduces more uncertainty. In traditional engineering, outcomes for a given effort are often easier to estimate, even if timelines slip.
In ML, the outcome itself is often unclear until you try, especially in adversarial settings. This makes iteration velocity, measurement discipline, and expectation management all critical parts of the job.
A common misconception about AI is that it’s full of magical breakthroughs. In practice, it’s empirical, iterative, and full of hard trade-offs. Most progress comes from structured experimentation and relentless tuning, not cleverness alone.
For those looking to break into ML roles at Big Tech companies:
Understand that interviews are highly structured. Prepare deliberately, but also develop real depth in the problem domains you’re interested in. That combination is what makes people stand out.