
Guide to Rapidly Improving AI Products Part 1
A 2-part deep dive on evaluation methods, data-driven improvements and experimentation techniques from helping 30+ companies build AI products!



Intro
How to improve AI products is a hot topic right now, as many companies are looking to either build a completely new AI product or add AI features to an existing product.
What’s common to both cases?
In both cases, it’s crucial to be able to ensure that the product works correctly and returns the correct results that users expect.
There are many ways to approach this and to ensure that we have the best insights, I am teaming up with Hamel Husain, ML Engineer with over 20 years of experience helping companies with AI.
This is a 2-part article for paid subscribers, with part 2 coming out next week on Wednesday.
Here is the full index for Part 1:
- 🎁 AI Evals FAQ
- Most AI Teams Focus on the Wrong Things
- 1. The Most Common Mistake: Skipping Error Analysis
- 2. The Error Analysis Process
- Bottom-Up vs. Top-Down Analysis
🔒 3. The Most Important AI Investment: A Simple Data Viewer
🔒 4. Empower Domain Experts To Write Prompts
🔒 Build Bridges, Not Gatekeepers
🔒 Tips For Communicating With Domain Experts
🔒 🎁 Notion Template: AI Communication Cheat Sheet
🔒 Last words
Introducing Hamel Husain
Hamel Husain is an experienced ML Engineer who has worked for companies such as GitHub, Airbnb, and Accenture, to name a few. Currently, he’s helping many people and companies to build high-quality AI products as an independent consultant.

Together with Shreya Shankar, they are teaching a popular course called AI Evals For Engineers & PMs. I highly recommend this course to build quality AI products as I have personally learned a lot from it.
Check the course and use my code GREGOR35 for 1050$ off. The cohort starts on October 6.
🎁 AI Evals FAQ
Before we begin today’s article, Hamel is kindly sharing a 27-page PDF with common questions and answers regarding AI Evals. These were the most common questions asked by the students on the course.
This PDF goes nicely together with the real-world case study on how to improve and evaluate an AI product. And also with the 2-part Guide to Rapidly Improving AI Products, which today is part 1.

Now, let’s get straight to the guide.
Most AI Teams Focus on the Wrong Things
Here’s a common scene from my consulting work:
AI Team Tech Lead:
Here’s our agent architecture → we’ve got RAG here, a router there, and we’re using this new framework for…
Me:
[Holding up my hand to pause the enthusiastic tech lead.]
“Can you show me how you’re measuring if any of this actually works?”
… Room goes quiet
This scene has played out dozens of times over the last two years. Teams invest weeks building complex AI systems, but can’t tell me if their changes are helping or hurting.
This isn’t surprising.
With new tools and frameworks emerging weekly, it’s natural to focus on tangible things we can control → which vector database to use, which LLM provider to choose, which agent framework to adopt.
But after helping 30+ companies build AI products, I’ve discovered the teams who succeed barely talk about tools at all. Instead, they obsess over measurement and iteration.
In this article, I’ll show you exactly how these successful teams operate.
1. The Most Common Mistake: Skipping Error Analysis
The “tools first” mindset is the most common mistake in AI development. Teams get caught up in architecture diagrams, frameworks, and dashboards while neglecting the process of actually understanding what’s working and what isn’t.
One client proudly showed me this evaluation dashboard:
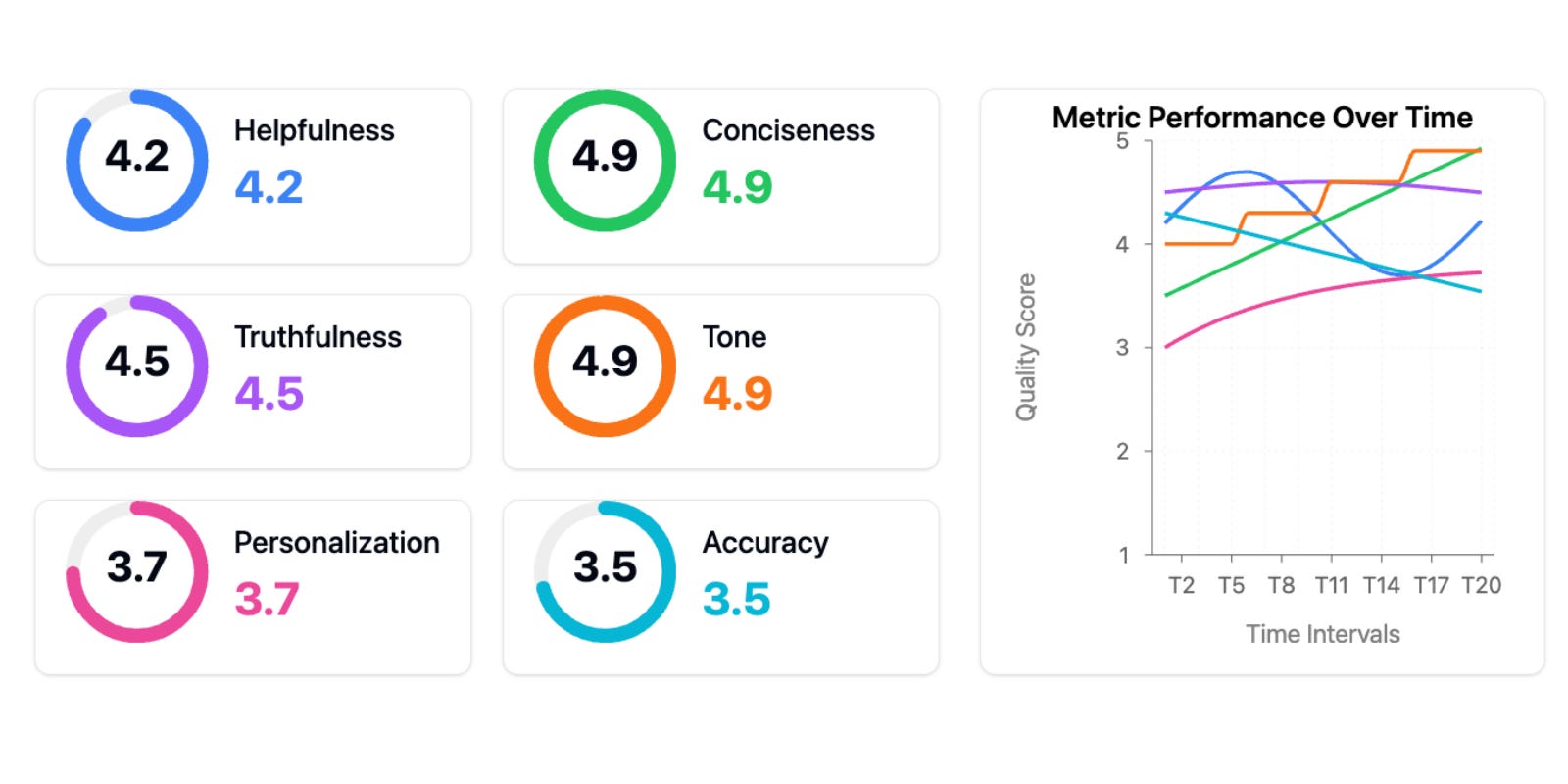
This is the “tools trap” → the belief that adopting the right tools or frameworks (in this case, generic metrics) will solve your AI problems.
Generic metrics are worse than useless → they actively impede progress in two ways:
They create a false sense of measurement and progress.
Teams think they’re data-driven because they have dashboards, but they’re tracking vanity metrics that don’t correlate with real user problems.
I’ve seen teams celebrate improving their “helpfulness score” by 10% while their actual users were still struggling with basic tasks. It’s like optimizing your website’s load time while your checkout process is broken → you’re getting better at the wrong thing.
Too many metrics fragment your attention.
Instead of focusing on the few metrics that matter for your specific use case, you’re trying to optimize multiple dimensions simultaneously.
When everything is important, nothing is.
The alternative?
Error analysis → the single most valuable activity in AI development and consistently the highest-ROI activity.
Let me show you what effective error analysis looks like in practice.
2. The Error Analysis Process
When Jacob, the founder of Nurture Boss, needed to improve their apartment-industry AI assistant, his team built a simple viewer to examine conversations between their AI and users.
Next to each conversation was a space for open-ended notes about failure modes. After annotating dozens of conversations, clear patterns emerged.
Their AI was struggling with date handling → failing 66% of the time when users said things like “let’s schedule a tour two weeks from now.”
Instead of reaching for new tools, they:
Looked at actual conversation logs
Categorized the types of date-handling failures
Built specific tests to catch these issues
Measured improvement on these metrics
The result? Their date handling success rate improved from 33% to 95%.
Bottom-Up vs. Top-Down Analysis
When identifying error types, you can take either a:
“top-down” or
“bottom-up” approach.
The top-down approach starts with common metrics like “hallucination” or “toxicity” plus metrics unique to your task. While convenient, it often misses domain-specific issues.
The more effective bottom-up approach forces you to look at actual data and let metrics naturally emerge.
At NurtureBoss, we started with a spreadsheet where each row represented a conversation. We wrote open-ended notes on any undesired behavior. Then we used an LLM to build a taxonomy of common failure modes.
Finally, we mapped each row to specific failure mode labels and counted the frequency of each issue.
The results were striking - just three issues accounted for over 60% of all problems:
Conversation flow issues (missing context, awkward responses)
Handoff failures (not recognizing when to transfer to humans)
Rescheduling problems (struggling with date handling)
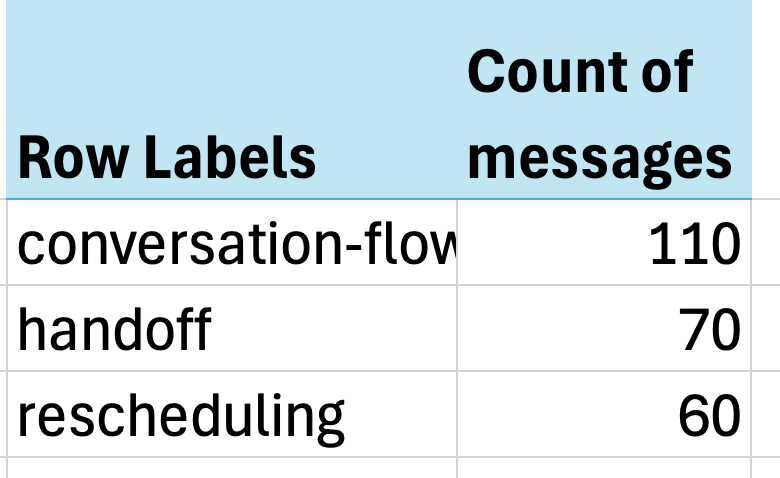
The impact was immediate. Jacob’s team had uncovered so many actionable insights that they needed several weeks just to implement fixes for the problems we’d already found.
If you’d like to see error analysis in action, we recorded a live walkthrough here.
This brings us to a crucial question: How do you make it easy for teams to look at their data?
The answer leads us to what I consider the most important investment any AI team can make…
3. The Most Important AI Investment: A Simple Data Viewer
 | A guest post by
|