
Guide to Rapidly Improving AI Products Part 2
Part 2 of the deep dive on evaluation methods, data-driven improvements and experimentation techniques from helping 30+ companies build AI products!



Intro
Correctly evaluating and continuously improving AI products is a really important topic. It’s what makes a difference between just a computer science experiment versus an actual useful AI product for the users.
There are many unrealistic expectations, especially from company leaders and I’ve personally heard a lot of horror stories like:
adding AI to existing features, because it's a shiny new thing that everyone is using these days,
enforcing AI usage with its people, or even worse,
company leaders vibe coding the homepage of the website and telling engineers how easy it is.
Lucky for us, we have Hamel Husain with us once again for Part 2 of the Guide to Rapidly Improving AI Products.
There are many highly relevant insights and we also go into fine details!
Hamel is sharing a lot of useful insights from his personal experience, including how to properly conduct a roadmap to build AI products.
Spoiler alert: A roadmap for building an AI product should look totally different than a roadmap for traditional Software Development!
This is an article for paid subscribers, and here is the full index:
- Sections 1 to 4 + 🎁
- 5. Populate Your AI With Synthetic Data Is Effective Even With Zero Users
- A Framework for Generating Realistic Test Data
- Guidelines for Using Synthetic Data
- 6. Maintaining Trust In Evals Is Critical
- Understanding Criteria Drift
🔒 Creating Trustworthy Evaluation Systems
🔒 6.1 Favor Binary Decisions Over Arbitrary Scales
🔒 6.2 Enhance Binary Judgments With Detailed Critiques
🔒 6.3 Measure Alignment Between Automated Evals and Human Judgment
🔒 Scaling Without Losing Trust
🔒 7. Your AI Roadmap Should Count Experiments, Not Features
🔒 Experiments vs. Features
🔒 The Foundation: Evaluation Infrastructure
🔒 Build a Culture of Experimentation Through Failure Sharing
🔒 A Better Way Forward
🔒 Conclusion
🔒 Last words
Introducing Hamel Husain
Hamel Husain is an experienced ML Engineer who has worked for companies such as GitHub, Airbnb, and Accenture, to name a few. Currently, he’s helping many people and companies to build high-quality AI products as an independent consultant.

Together with Shreya Shankar, they are teaching a popular course called AI Evals For Engineers & PMs. I highly recommend this course to build quality AI products as I have personally learned a lot from it.
Check the course and use my code GREGOR35 for 1050$ off. The early bird discount ends this Friday.
Sections 1 to 4 + 🎁
Make sure to also read the first part, where we shared:
🎁 AI Evals FAQ
1. The Most Common Mistake: Skipping Error Analysis
2. The Error Analysis Process
3. The Most Important AI Investment: A Simple Data Viewer
4. Empower Domain Experts To Write Prompts
🎁 Notion Template: AI Communication Cheat Sheet
You can read the Part 1 here:

And now, we are diving deeper into populating your AI with synthetic data, how to maintain trust in evals, and how to structure your AI roadmap.
Hamel, over to you!
5. Populate Your AI With Synthetic Data Is Effective Even With Zero Users
One of the most common roadblocks I hear from teams is:
“We can’t do proper evaluation because we don’t have enough real user data yet.”
This creates a chicken-and-egg problem → you need data to improve your AI, but you need a decent AI to get users who generate that data.
Fortunately, there’s a solution that works surprisingly well: synthetic data. LLMs can generate realistic test cases that cover the range of scenarios your AI will encounter.
Bryan Bischof, the former Head of AI at Hex, put it perfectly:
“LLMs are surprisingly good at generating excellent and diverse examples of user prompts. This can be relevant for powering application features, and sneakily, for building Evals. If this sounds a bit like the Large Language Snake is eating its tail, I was just as surprised as you! All I can say is: it works, ship it.”
A Framework for Generating Realistic Test Data
The key to effective synthetic data is choosing the right dimensions to test. While these dimensions will vary based on your specific needs, I find it helpful to think about three broad categories:
Features: What capabilities does your AI need to support?
Scenarios: What situations will it encounter?
User Personas: Who will be using it and how?
These aren’t the only dimensions you might care about → you might also want to test different tones of voice, levels of technical sophistication, or even different locales and languages. The important thing is identifying dimensions that matter for your specific use case.
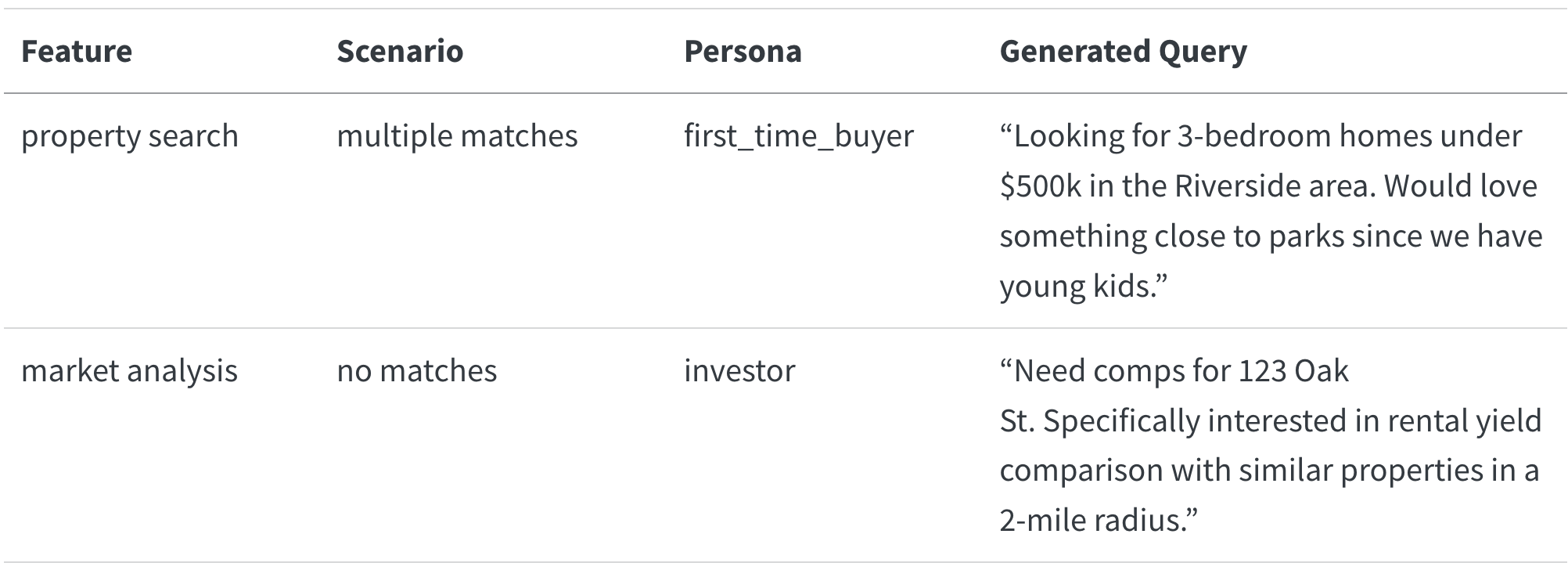
For a real estate CRM AI assistant I worked on with Rechat, we defined these dimensions like this:
features = [
"property search", # Finding listings matching criteria
"market analysis", # Analyzing trends and pricing
"scheduling", # Setting up property viewings
"follow-up" # Post-viewing communication
]
scenarios = [
"exact match", # One perfect listing match
"multiple matches", # Need to help user narrow down
"no matches", # Need to suggest alternatives
"invalid criteria" # Help user correct search terms
]
personas = [
"first_time_buyer", # Needs more guidance and explanation
"investor", # Focused on numbers and ROI
"luxury_client", # Expects white-glove service
"relocating_family" # Has specific neighborhood/school needs
]But having these dimensions defined is only half the battle. The real challenge is ensuring your synthetic data actually triggers the scenarios you want to test. This requires two things:
A test database with enough variety to support your scenarios
A way to verify that generated queries actually trigger intended scenarios
For Rechat, we maintained a test database of listings that we knew would trigger different edge cases. Some teams prefer to use an anonymized copy of production data, but either way, you need to ensure your test data has enough variety to exercise the scenarios you care about.
Here’s an example of how we might use these dimensions with real data to generate test cases for the property search feature (this is just pseudo-code, and very illustrative):
def generate_search_query(scenario, persona, listing_db):
"""Generate a realistic user query about listings"""
# Pull real listing data to ground the generation
sample_listings = listing_db.get_sample_listings(
price_range=persona.price_range,
location=persona.preferred_areas
)
# Verify we have listings that will trigger our scenario
if scenario == "multiple_matches" and len(sample_listings) < 2:
raise ValueError("Need multiple listings for this scenario")
if scenario == "no_matches" and len(sample_listings) > 0:
raise ValueError("Found matches when testing no-match scenario")
prompt = f"""
You are an expert real estate agent who is searching for listings. You are given a customer type and a scenario.
Your job is to generate a natural language query you would use to search these listings.
Context:
- Customer type: {persona.description}
- Scenario: {scenario}
Use these actual listings as reference:
{format_listings(sample_listings)}
The query should reflect the customer type and the scenario.
Example query: Find homes in the 75019 zip code, 3 bedrooms, 2 bathrooms, price range $750k - $1M for an investor.
"""
return generate_with_llm(prompt)This produced realistic queries like:
The key to useful synthetic data is grounding it in real system constraints. For the real-estate AI assistant, this means:
Using real listing IDs and addresses from their database
Incorporating actual agent schedules and availability windows
Respecting business rules like showing restrictions and notice periods
Including market-specific details like HOA requirements or local regulations
We then feed these test cases through Lucy (Rechat’s AI assistant) and log the interactions.
This gives us a rich dataset to analyze, showing exactly how the AI handles different situations with real system constraints. This approach helped us fix issues before they affected real users.
Sometimes you don’t have access to a production database, especially for new products. In these cases, use LLMs to generate both test queries and the underlying test data.
For a real estate AI assistant, this might mean creating synthetic property listings with realistic attributes → prices that match market ranges, valid addresses with real street names, and amenities appropriate for each property type.
The key is grounding synthetic data in real-world constraints to make it useful for testing. The specifics of generating robust synthetic databases are beyond the scope of this article.
Guidelines for Using Synthetic Data
When generating synthetic data, follow these key principles to ensure it’s effective:
Diversify your dataset: Create examples that cover a wide range of features, scenarios, and personas. This diversity helps you identify edge cases and failure modes you might not anticipate otherwise.
Generate user inputs, not outputs: Use LLMs to generate realistic user queries or inputs, not the expected AI responses. This prevents your synthetic data from inheriting the biases or limitations of the generating model.
Incorporate real system constraints: Ground your synthetic data in actual system limitations and data. For example, when testing a scheduling feature, use real availability windows and booking rules.
Verify scenario coverage: Ensure your generated data actually triggers the scenarios you want to test. A query intended to test “no matches found” should actually return zero results when run against your system.
Start simple, then add complexity: Begin with straightforward test cases before adding nuance. This helps isolate issues and establish a baseline before tackling edge cases.
This approach isn’t just theoretical → it’s been proven in production across dozens of companies. What often starts as a stopgap measure becomes a permanent part of the evaluation infrastructure, even after real user data becomes available.
Let’s look next at how to maintain trust in your evaluation system as you scale.
6. Maintaining Trust In Evals Is Critical
This is a pattern I’ve seen repeatedly:
Teams build evaluation systems, then gradually lose faith in them.
Sometimes it’s because the metrics don’t align with what they observe in production. Other times, it’s because the evaluations become too complex to interpret.
Either way, the result is the same → the team reverts to making decisions based on gut feeling and anecdotal feedback, undermining the entire purpose of having evaluations.
Maintaining trust in your evaluation system is just as important as building it in the first place. Here’s how the most successful teams approach this challenge:
Understanding Criteria Drift
One of the most insidious problems in AI evaluation is “criteria drift” → a phenomenon where evaluation criteria evolve as you observe more model outputs.
In their paper “Who Validates the Validators?”, Shankar et al. describe this phenomenon:
“To grade outputs, people need to externalize and define their evaluation criteria; however, the process of grading outputs helps them to define that very criteria.”
This creates a paradox: you can’t fully define your evaluation criteria until you’ve seen a wide range of outputs, but you need criteria to evaluate those outputs in the first place.
In other words, it is impossible to completely determine evaluation criteria prior to human judging of LLM outputs.
I’ve observed this firsthand when working with Phillip Carter at Honeycomb on their Query Assistant feature. As we evaluated the AI’s ability to generate database queries, Phillip noticed something interesting:
“Seeing how the LLM breaks down its reasoning made me realize I wasn’t being consistent about how I judged certain edge cases.”
The process of reviewing AI outputs helped him articulate his own evaluation standards more clearly.
This isn’t a sign of poor planning → it’s an inherent characteristic of working with AI systems that produce diverse and sometimes unexpected outputs.
The teams that maintain trust in their evaluation systems embrace this reality rather than fighting it. They treat evaluation criteria as living documents that evolve alongside their understanding of the problem space.
They also recognize that different stakeholders might have different (sometimes contradictory) criteria, and they work to reconcile these perspectives rather than imposing a single standard.
Creating Trustworthy Evaluation Systems
So how do you build evaluation systems that remain trustworthy despite criteria drift?
Here are the approaches I’ve found most effective:
 | A guest post by
|