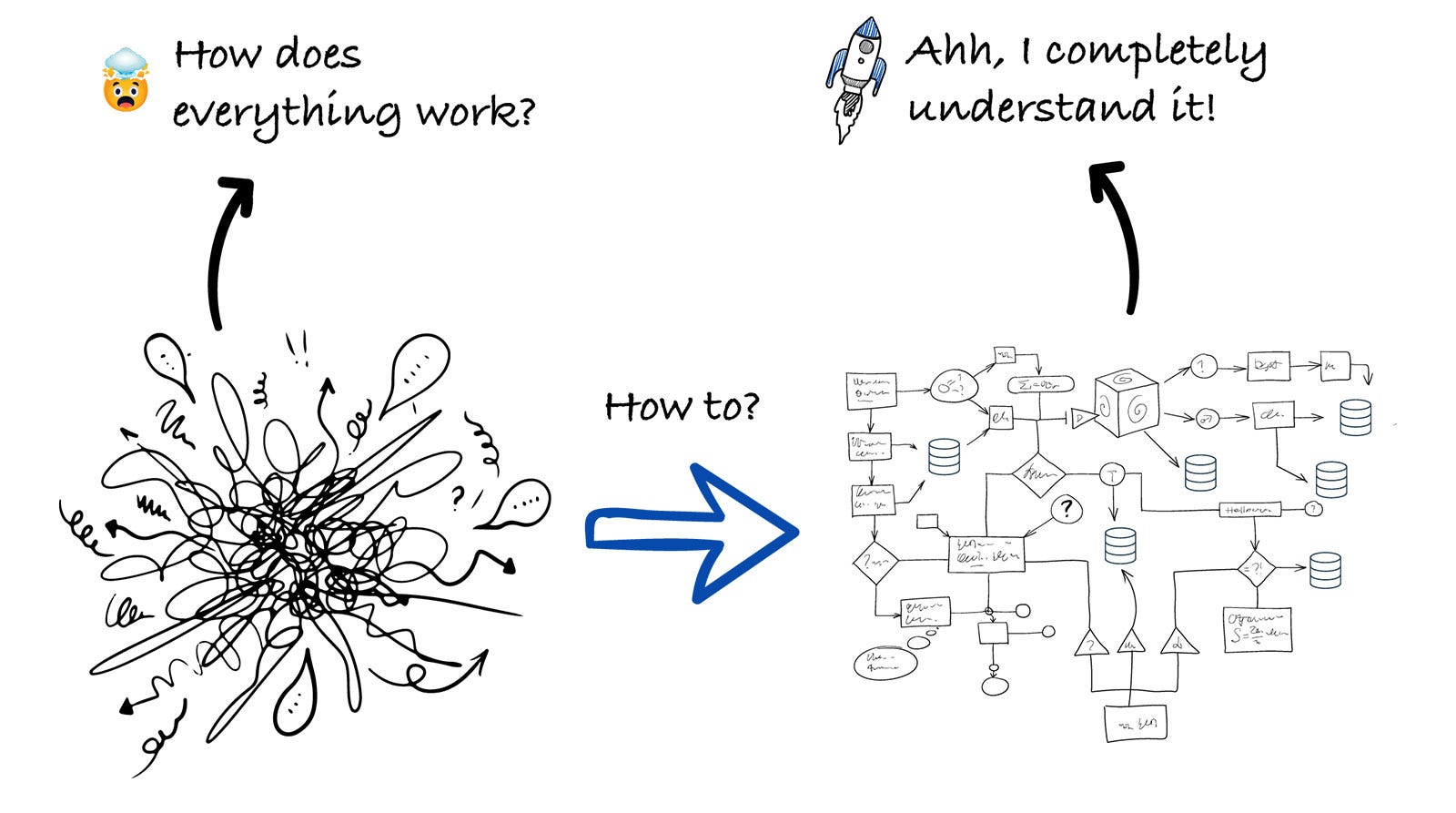
How to Use AI to Onboard Into a Codebase Faster4 onboarding steps to speed up your understanding of a codebase and get you up and running in a few hours!Gregor Ojstersek and Jeff MorhousMay 10, 2026∙ Paid1041210ShareThis post is for paid subscribersSubscribeAlready a paid subscriber? Sign in